Attention Is All You Need
NIPS 📆 2017
大多数有竞争力的神经序列转导模型具有编码器-解码器结构。
attention
一个 attention 函数可以描述为将一个查询和一组键值对映射为输出。输出通过每个值的加权和计算得出,其中分配给每个值的权重由查询和对应键的一致性函数计算得出。
Transformer 是一个 sequence-to-sequence 模型,一个序列进来,一个序列出去。
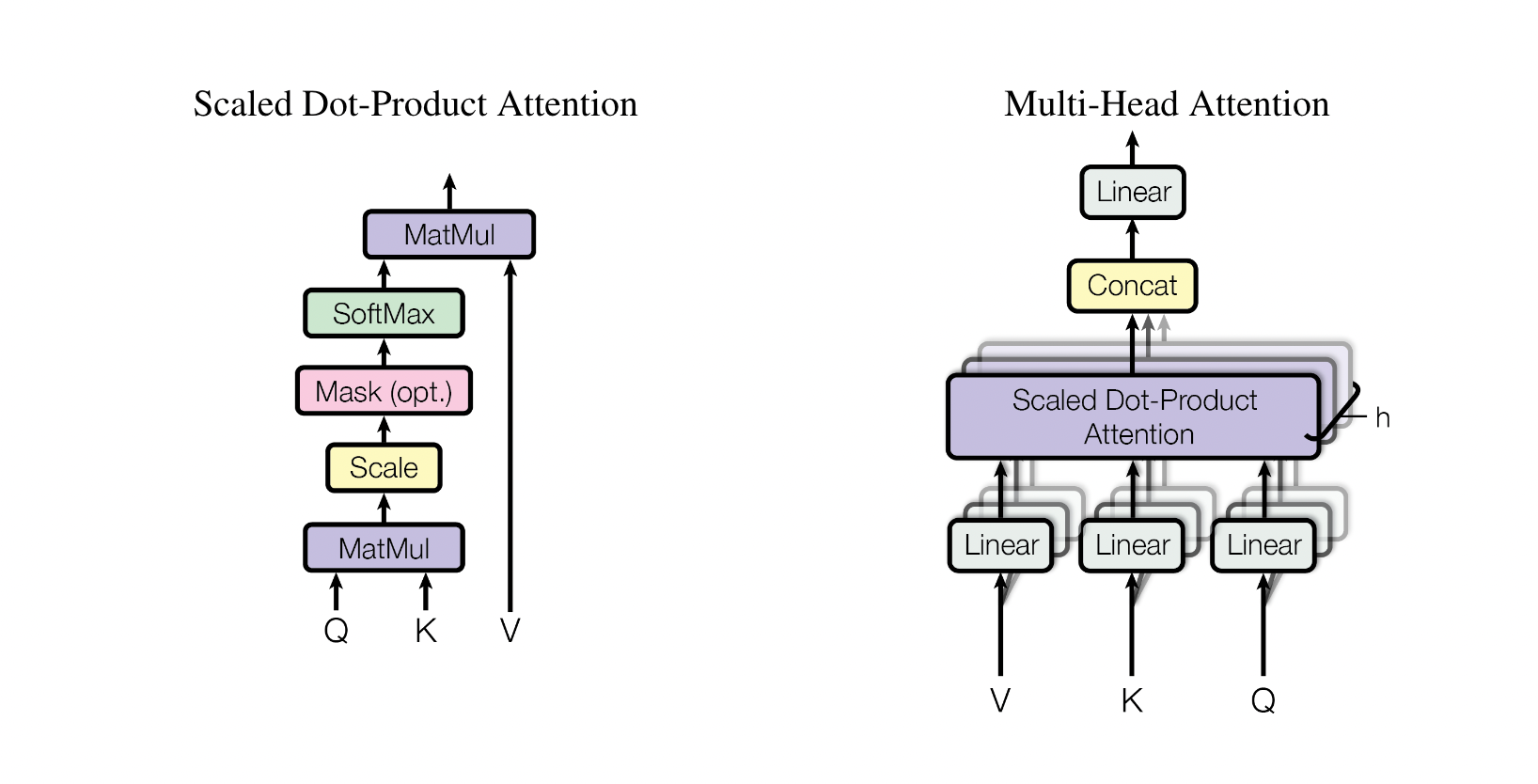
attention 三步走
- query 和 key 进行相似度计算,得到一个query 和 key 相关性的分数;
- 将这个分数进行归一化(softmax),得到一个注意力的分布;
- 使用注意力分布和 value 相乘,得到一个融合注意力的更好的 value 值。
The Transformer - model architecture.
为什么 attention 是有效的
学习远程依赖是许多序列建模任务中的一个关键挑战。
两大优点
- 可以捕捉长距离依赖关系,使得其在处理序列数据,特别是自然语言处理时,表现出很好的性能。
- 并行计算:与 RNN 和 LSTM 等序列模型不同,自注意力机制在处理序列数据时进行并行计算,这大大提高了计算效率。
那为何加了位置编码就能获取数据间位置的特征呢? 在self-attention的结构中,在对每维数据计算权重时,是采用点积的形式,本质上就是计算向量之间的相关性。 而位置编码将临近的数据加上频率接近的位置编码,就是增加了相邻数据的相关性。
self-attention是BERT的重要思想,其与位置编码结合,解决了文本数据的时序相关性的问题,从而一举结束了依靠RNN、LSTM、GRU等之前一直用来解决时序问题的网络模型。
代码实现
https://tunz.kr/post/4
http://nlp.seas.harvard.edu/2018/04/03/attention.html
http://nlp.seas.harvard.edu/annotated-transformer/
References
[1] Peter Bloema, transformers from scratch
[2] Patrick von Platen, Transformers-based Encoder-Decoder Models
[3] 打工仔, 保姆级分析self Attention为何除根号d,看不懂算我的
[4] 奥辰, Transformer算法完全解读