DiT: Self-supervised Pre-training for Document Image Transformer
Abstract
作者提出了一种自监督的预训练文档图像Transformer模型,称为 DiT。 由于缺乏人工标注的文档图像,DiT 使用大规模无标记文本图像来执行任务。
Introduction
最近几年,自监督训练技术已经成为文档AI任务的常用方案。 预训练文档AI模型通常基于视觉的理解,例如光学字符识别或文档布局分析,这些严重依赖于经过人工标注训练的有监督模型。 由于域偏移问题和训练数据的模版/格式不匹配,这些模型在实际应用中的性能表现并不理想。 因此,如何利用自监督预训练作为文档图像理解的骨干网络,从而促进不同领域的通用文档模型是不可避免的。
To This End 👉 提出 DiT,一个不依赖于人工标注文档图像的模型。
受 BEiT 模型的启发。但与 BEiT 不同的是,BEiT 模型中的视觉标注来自 DALL-E 中的离散 VAE, 而 DiT 使用大规模文档图像重新训练离散 VAE(dVAE),以便生成的标注与领域更加相关。
预训练的目的是使用 BEiT 中的掩码图像建模(MIM)根据损坏的输入文档图像从 dVAE 恢复视觉 token,从而学习每个文档图像内的全局补丁关系。
论文贡献:
-
提出了 DiT,一种自监督的预训练文档图像 Transformer 模型,它可以利用大规模无标记文档图像进行预训练。
-
利用预训练 DiT 模型作为各种文档 AI 任务的主干网络,包括文档图像分类、文档布局分析、表格检测以及 OCR 文本检测,并取得了新的最先进的结果。
-
代码和预训练模型可在 https://aka.ms/msdit 上公开获取。
Architecture
遵循 ViT,模型使用普通 Transformer 作为主干网络。 将文档图像划分为不重叠的补丁并获得一补丁嵌入序列。 添加一维位置编码后,这些补丁被送入 Transformer 堆栈中。 最后,将 Transformer 编码器的输出作为图像补丁的表示。
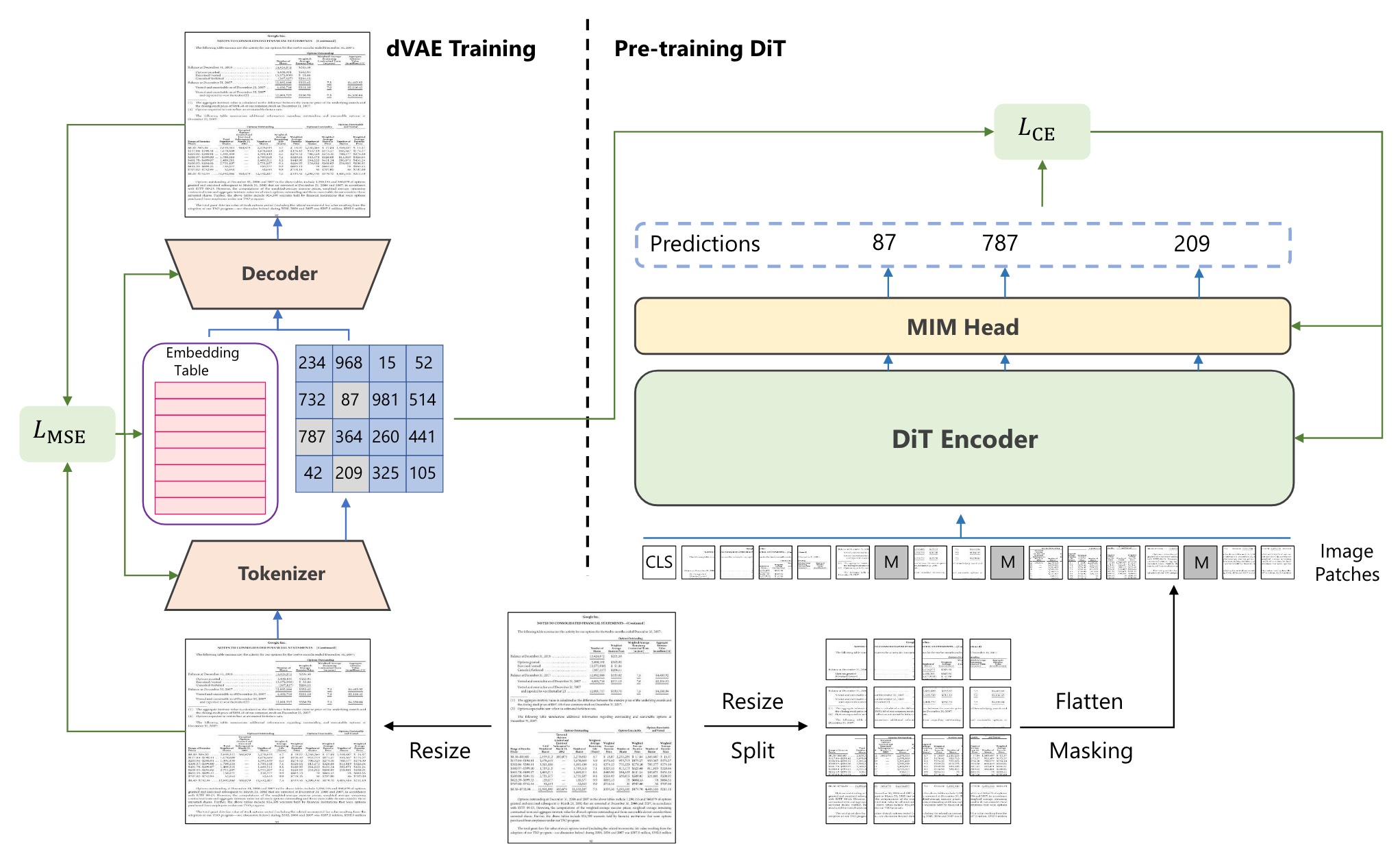
The model architecture of DiT with MIM pre-training.
Pre-training
在预训练过程中,一个图像分别表示为图像补丁和视觉 token 。 在此期间,DiT 接受图像块作为输入,并使用输出表示来预测视觉 token 。 与自然语言中的文本 token 一样,图像可以表示为由图像分词器获得的一个离散token序列。 BEiT 使用 DALLE 的离散变分自编码器(dVAE)作为图像分词器,它在包括 4 亿张图像的大型数据集上进行训练。 然而,自然图像和文档图像之间存在域不匹配,这使得 DALL-E 分词器不适合文档图像。 因此,为了获得文档图像域更好的离散视觉token ,作者在包含 4200 万文档图像的 IIT-CDIP 数据集上训练 dVAE。 为了有效地预训练 DiT 模型,作者在给定图像补丁序列的情况下使用特殊 token [MASK] 随机屏蔽输入子集。 DiT 编码器通过添加位置嵌入的线性投影来嵌入屏蔽补丁序列,然后将其与一堆 Transformer 块结合起来。 该模型需要使用屏蔽位置的输出来预测视觉 token 的索引。 掩码图像建模任务不需要预测原始像素,而是要求模型预测图像分词器获得的离散视觉 token 。
Fine-tuning
图像分类:对于图像分类,作者使用平均池化来聚合图像补丁的表示。 然后,作者将全局表示传递到一个简单的线性分类器中。
目标检测:对于目标检测,作者利用 Mask R-CNN 和 Cascade R-CNN 作为检测框架,并使用基于 ViT 的模型作为主干。 作者利用特征金字塔的思想,从 Transformer 堆栈中提取四个 Transformer 块进行融合,使得模型具备多尺度信息。 对提取出的四个不同的 Transformer 使用分辨率修改模块,然后送入FPN。
令 d 为总块数,分别对第 1d/3、 1d/2、 2d/3、3d/3 的 Transformer 块进行上采样或下采样。
- 第 1d/3 个:使用两次步长为2的 2×2 转置卷积的模块对块进行4倍上采样。
- 第 1d/2 个:使用一次步长为2的 2×2 转置卷积来2倍上采样。
- 第 2d/3 个:输出无需额外操作即可使用。
- 第 3d/3 个:使用一次步长为2的 2×2 最大池化进行2倍下采样。
这些模块中的第一个使用跨步 2×2 转置卷积将特征图上采样 4 倍,然后是组归一化 [39] 和 GeLU [21],最后是另一个跨步 2×2 转置卷积。 使用单步长-2 2 × 2 转置卷积对下一个 d/4 块的输出进行 2× 上采样(没有归一化和非线性)。 下一个 d/4 块的输出按原样获取,最终 ViT 块的输出使用跨步 2 2 × 2 最大池化按两倍下采样。 每个模块都保留 ViT 的嵌入/通道维度。假设补丁大小为 16,这些模块生成步幅为 4、8、16 和 32 像素的特征图。输入图像,准备输入 FPN。
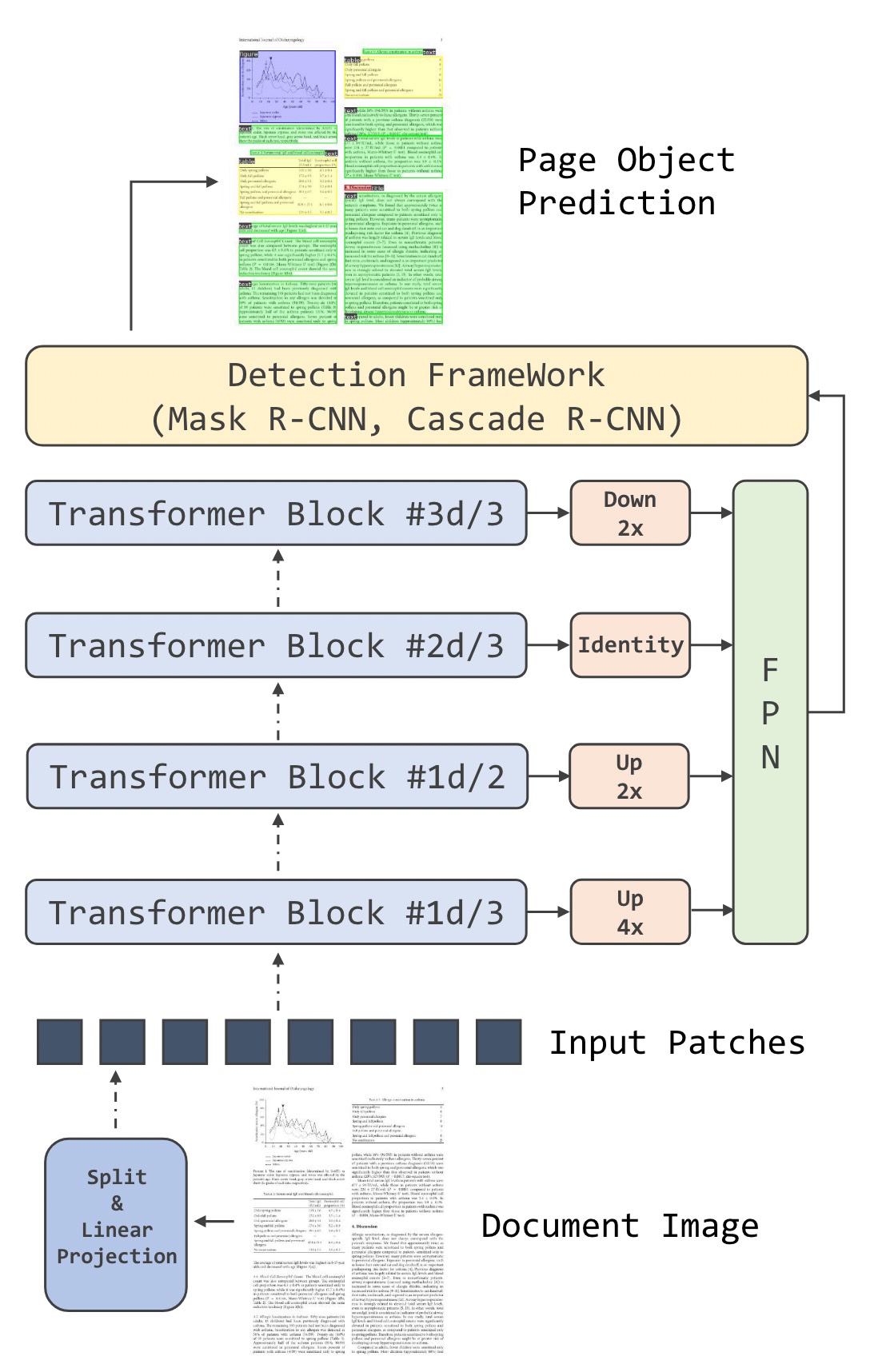
Illustration of applying DiT as the backbone network in different detection frameworks.
DiT: https://aka.ms/msdit
dVAE: https://github.com/lucidrains/DALLE-pytorch