BEiT: BERT Pre-Training of Image Transformers
arXiv 📆 2022-9-3
Abstract
作者提出了一种掩码图像建模任务用来预训练 vision Transformers。 作者将这个自监督模型命名为 BEiT(Bidirectional Encoder representation from Image Transformer)。 在预训练过程中,每个图像都有两个视图:图像补丁和视觉 token。图像用于输入,token 用于输出。 首先,原始图像被 tokenize 为视觉 token,然后随机屏蔽一些图像补丁并将他们输入主干 Transformer 中。 根据损坏的图像补丁恢复原始视觉 token 来达到预训练的目的。
Introduction
Transformer 已经在图像领域取得了出色的成绩,然而视觉 Transformer 比卷积神经网络需要更多的训练数据。 为了解决数据匮乏问题,自监督训练是利用大规模图像数据的一种有前景的方案。 针对视觉 Transformer,目前已经探索了多种方法,例如对比学习和自蒸馏。
受 BERT 的启发,作者利用去躁自动编码的思想来预训练视觉 Transformer。 直接对图像数据应用 BERTstyle 预训练具有挑战性。 首先,视觉 Transformer 的输入单元(即图像块)没有预先存在的词汇表。 因此,我们不能简单地使用 softmax 分类器来预测屏蔽补丁的所有可能候选者。 相比之下,语言词汇(例如单词和 BPE )定义明确,并且简化了自动编码预测。 一个简单的替代方案是将任务视为回归问题,它预测掩码补丁的原始像素。 然而,这种像素级恢复任务往往会浪费预训练短程依赖性和高频细节的建模能力。 因此,BEiT 学习恢复原始图像的视觉 token,而不是掩码补丁的原始像素。
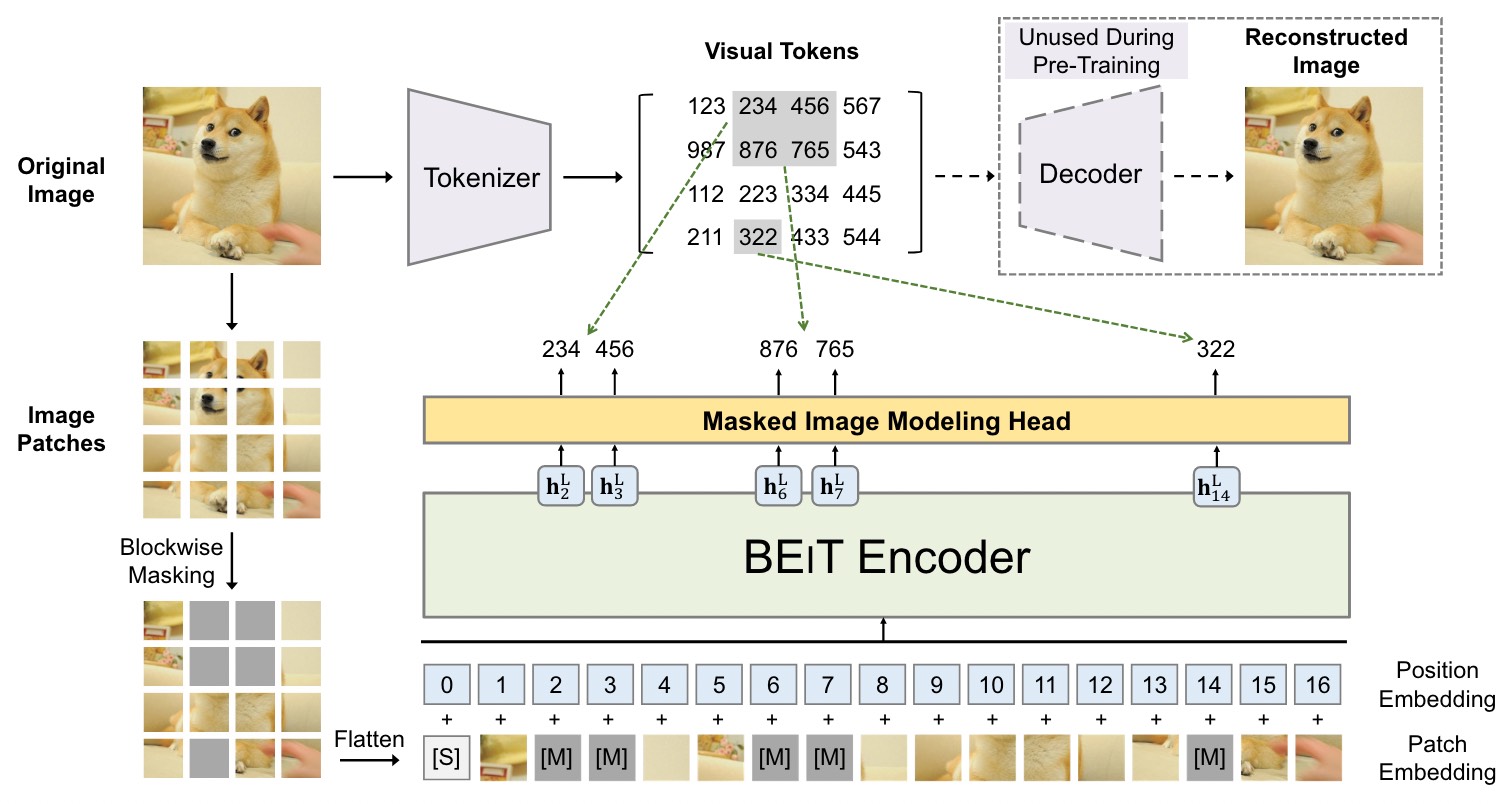
Overview of BEiT pre-training.
论文贡献:
-
提出了一种掩码图像建模任务,以自我监督的方式预训练视觉 Transformer。我们还从变分自动编码器的角度提供了理论解释。
-
对 BEIT 进行预训练,并对下游任务(例如图像分类和语义分割)进行广泛的微调实验。
-
提出自监督 BEIT 的自注意力机制能够学习区分语义区域和对象边界,尽管没有使用任何人工标注。
Methods
给定输入图像 x, BEiT 将其编码为上下文向量表示。 BEiT 通过掩模图像建模(MIM)任务以自监督学习的方式进行预训练。 MIM 旨在基于编码向量恢复掩模图像块。 对于下游任务(例如图像分类和语义分割),在预训练的 BEiT 上附加任务层,并在特定数据集上微调参数。
图像表示
在 BEit中,图像有两种表示形式,即图像补丁和视觉 token。这两种形式在预训练期间分别被用作输入和输出表示。
图像补丁
2 维的图像会被分割成补丁序列,作为标准 Transformer 可以直接接收的数据形式。 图像补丁再被展平为向量然后对其施加线性投影,类似于 BERT 中的词嵌入。 经过处理后的图像补丁保留原始像素并用作 BEiT 中的输入特征。 实验中,每个 224✖️224 的图像被分割为 14✖️14 的图像补丁网格,其中每个补丁为 16✖️16。
1224✖️224 = (14✖️14)✖️(16✖️16)
视觉 token
与 NLP 任务类似,BEiT 利用图像分词器将图像转换为视觉 token。 分词器使用离散变分自编码器(dVAE)学习的图像分词器。 在视觉 token 的学习过程中有两个模块:分词器和解码器。 分词器根据视觉码本将图像像素 x 映射为离散 token z,解码器学习基于视觉 token z 重建输入图像 x。 由于潜在视觉 token 是离散的,因此模型训练是不可微的。 所以采用 Gumbel-softmax relaxation 来训练模型参数。 此外,在 dVAE 训练期间,对分词器施加统一的先验。 每个图像被分为 14✖️14 的视觉 token 网格。 一副图像的视觉 toekn 数量和图像补丁数量是相同。 词汇量大小设置为 8192。 该工作中直接使用了 DALL-E 中的图像分词器。
主干网络
遵循 ViT,论文使用标准 Transformer 作为主干网络。 主干网络的输入是图像补丁序列。 将图像补丁线性投影得到补丁嵌入。 额外的,添加一个特殊的 token [S] 到输入输入序列中。 然后将 1 维可学习的位置嵌入加入到补丁嵌入中。 得到的嵌入向量作为 Transformer 的输入。 编码器的最后一层 Transformer 块的输出作为图像块的编码表示。
预训练 BEiT
论文提出了掩码图像建模(MIM)任务。 通过随机屏蔽一定比例的图像补丁,然后预测屏蔽补丁对应的视觉 token。
变分自编码器视角
Code
⌨️
https://aka.ms/beit
https://github.com/openai/DALL-E
References
[1] Self-Supervised Learning 超详细解读 (三):BEiT:视觉BERT预训练模型 http://nooverfit.com/wp/回顾bert优势与劣势:深入理解这些无监督怪兽,及/ https://cloud.tencent.com/developer/article/1389555 https://blog.csdn.net/qq_39478403/article/details/128125376